

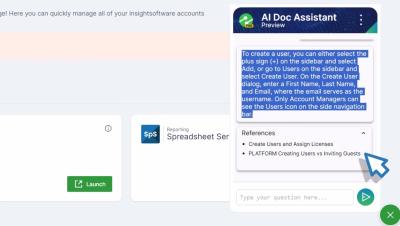
Get to know the AI Doc Assist in Platform
Searching through documentation websites or knowledge-based articles to get answers to your specific query is time-consuming? The AI Doc Assist feature in the Platform is a fantastic help. Learn how to leverage the capabilities of AI Doc Assist.






